In this post, we are going to look at the different web scraping tools available, both commercial and open-source.
There are many tools on the market, and it can be hard to make a choice.
To help you make your choice, I'm going to briefly explain what each tool does and what you should use depending on your needs.
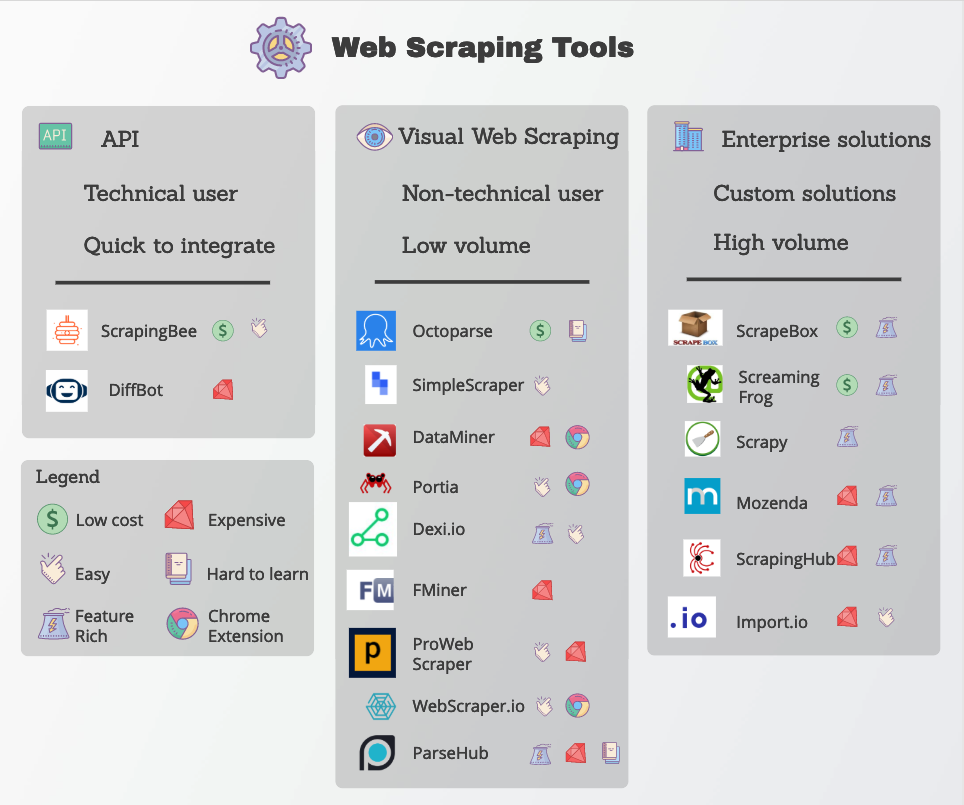
Top Web Scraping Tools
1. ScrapingBee
ScrapingBee is a web scraping API that allows you to scrape the web without getting blocked. We offer both classic (data-center) and premium (residentials) proxies so you will never get blocked again while scraping the web.
We also give you the opportunity to render all pages inside a real browser (Chrome), this allows us to support website that heavily rely on Javascript).
Who should use this web scraping tool?
ScrapingBee is for developers and tech companies who want to handle the scraping pipeline themselves without taking care of proxies and headless browsers
Pro:
- Easy integration
- Great documentation
- Great Javascript rendering
- Cheaper than buying proxies, even for a large number of requests per month
Cons:
- Cannot be used without having in-house developers
2. DiffBot
DiffBot offers multiple APIs that return structured data of products/article/discussion web pages. Their solution is quite expensive with the lowest plan beginning at $299 per month.
Who should use this web scraping tool?
Diffbot is for developers and tech companies.
Developing in-house web scrapers is painful because websites are constantly changing. Let's say you are scraping ten news websites. You need ten different rules (XPath, CSS selectors...) to handle the different cases.
Diffbot can take care of this with their automatic extraction APIs.
Pro:
- Easy integration
Cons:
- Doesn't work on every websites
- Expensive
3. ScrapeBox
ScrapeBox is a desktop software that allow you to do many thing related to web scraping. From email scraper to keyword scraper they claim to be the swiss army knife of SEO.
Who should use this web scraping tool?
SEO professionals and agencies.
Pro:
- Run on your local machine
- Low cost (one time payment)
- Feature-rich
Cons:
- Slow for large scale scraping
4. ScreamingFrog
ScreamingFrog is a website crawler for Windows, macOS and Ubuntu. It allows you to crawl websites’ URLs to analyze and perform technical audit and onsite SEO. It is able to crawl both small and large websites efficiently, while allowing you to analyze the results in real-time.
Who should use this web scraping tool?
SEO professionals and agencies.
Pro:
- Runs on your local machine
- Low-cost (one-time payment)
- Feature-rich
Cons:
- Slow for large-scale scraping
5. Scrapy
Scrapy is a free open-source web-crawling framework written in Python. Originally designed for web scraping, it can also be used to extract data using APIs or as a general-purpose web crawler.
Who should use this web scraping tool?
Scrapy is for developers and tech companies with Python knowledge.
Scrapy is great for large-scale web scraping with repetitive tasks:
- Extracting e-commerce product data
- Extracting articles from news websites
- Crawling an entire domain to get every URL
Pro:
- Lots of features to solve the most common web scraping problems
- Actively maintained
- Great documentation
Cons:
- None
6. Import.io
Import.io is an enterprise web scraping platform. Historically they had a self-serve visual web scraping tool.
Who should use this web scraping tool?
Import.io is for large companies who want a no-code/low-code web scraping tool to easily extract data from websites.
Pro:
- One of the best UIs
- Easy to use
Cons:
- The tool is self-serve, meaning you won't get much help if you have problems with it.
- Expensive like many other visual web scraping tools
7. Frontera
Frontera is another web crawling tool.
It is an open-source framework developed to facilitate building a crawl frontier. A crawl frontier is the system in charge of the logic and policies to follow when crawling websites, it plays a key role in more sophisticated crawling systems. It sets rules about which pages should be crawled next, visiting priorities and ordering, how often pages are revisited, and any behavior you may want to build into the crawl.
It can be used with Scrapy or any other web crawling framework.
Who should use this web scraping tool?
Frontera is great for developers and tech companies with a Python stack.
Pro:
- Open-source
- Free
- Great for large-scale web crawling
Cons:
- Not actively maintained, last commit is from 2019
- For crawling only
- Not very popular
8. PySpider
PySpider is another open-source web crawling tool. It has a web UI that allows you to monitor tasks, edit scripts and view your results.
Who should use this web scraping tool?
Frontera is great for developers and tech companies with a Python stack.
Pro:
- Open-source
- Popular (14K Github stars) and active project
- Solves lots of common web scraping problems
- Powerful web UI
Cons:
- Steep learning curve
- Uses PhantomJS to render Javascript page, which is inferior to Headless Chrome
Honorable mention
Mozenda
Mozenda is an enterprise web scraping software designed for all kinds of data extraction needs. They claim to work with 30% of the fortune 500, for use cases like large-scale price monitoring, market research, competitor monitoring.
They can build and host the scraper for you
Who should use this web scraping tool?
Mozenda is for enterprises with large data extraction projects.
Pro:
- Great for big companies
- Can be integrated into any system
- Can even scrape PDFs
Cons:
- Expensive
ScrapingHub
ScrapingHub is one of the most well-known web scraping companies. They have a lot of product web scraping products, both open-source and commercial. Scrapinghub is the company behind the Scrapy framework and Portia. They offer Scrapy hosting, meaning you can easily deploy your Scrapy spiders to their cloud.
Who should use this web scraping tool?
Scrapinghub is for tech companies and individual developers. It offers lots of developers' tools for web scraping.
Pro:
- Lots of different products for different use cases
- Best hosting for Scrapy projects
Cons:
- Pricing is tricky and can quickly become expensive compared to other options
- Support seems slow to respond
Goutte
Goutte is a screen scraping and web crawling library for PHP.
Goutte provides a nice API to crawl websites and extract data from the HTML/XML responses.
It also integrates nicely with the Guzzle requests library, which allows you to customize the framework for more advanced use cases.
Who should use this web scraping tool?
Goutte is for developers and tech companies with PHP knowledge.
Pro:
- Open-source
- Free
- Actively maintained
Cons:
- Less popular than Scrapy
- Fewer integrations than Scrapy
Dexi.io
Dexi.io is a visual web scraping platform. One of the most interesting features is that they offer built-in data flows. This means not only you can scrape data from external websites, but also transform the data, using external APIs (like Clearbit, Google Sheets, etc).
Who should use this web scraping tool?
Dexi.io is for teams without developers that want to quickly scrape websites and transform the data.
Pro:
- Intuitive interface
- Data pipeline
- Lots of integration
Cons:
- Pricey
- Not very flexible
WebScraper.io
WebScraper is one of the most popular Chrome extension tools. It allows you to scrape any website without writing a single line of code, directly inside Chrome!
Here is a screenshot of the interface (accessible within the Chrome dev tools):
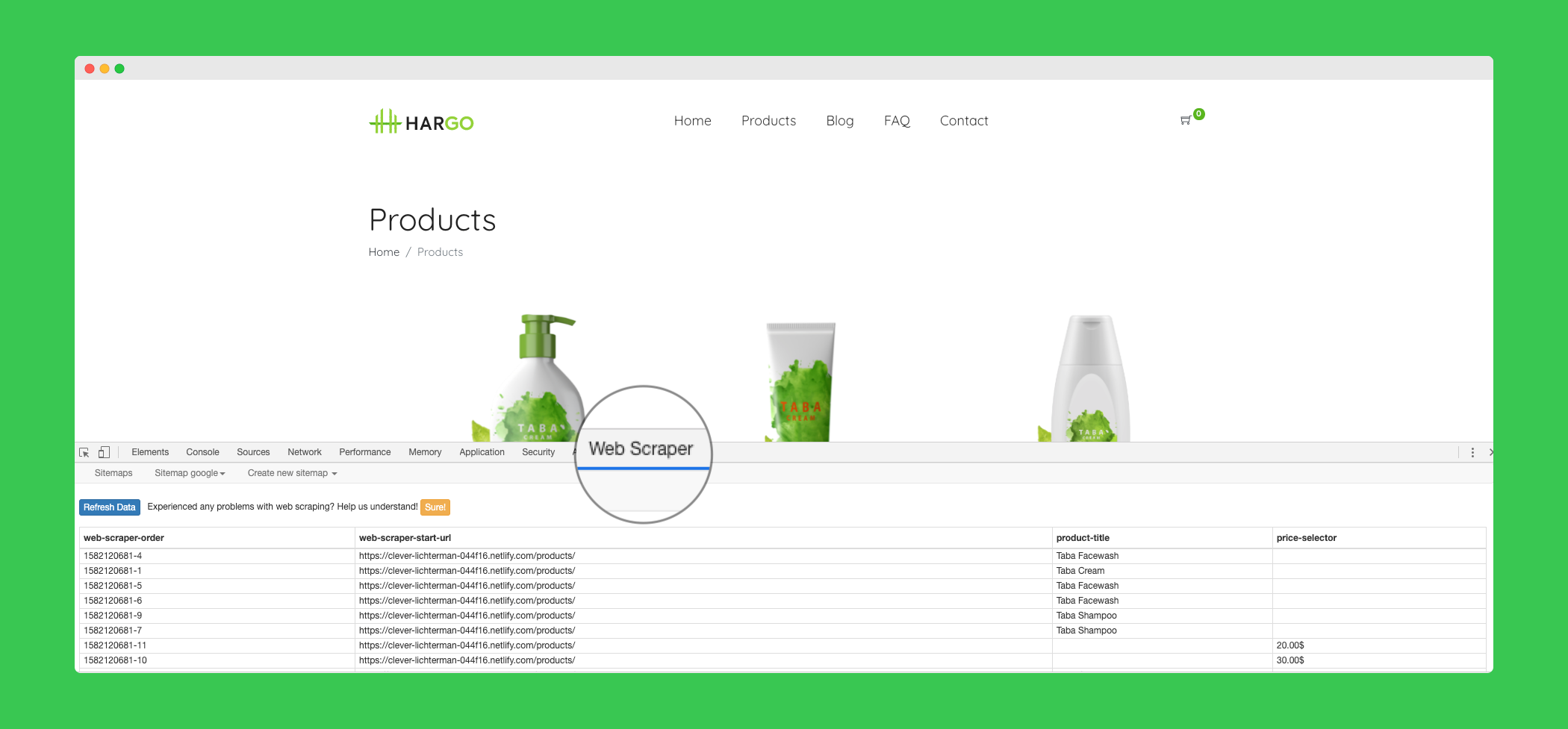
Here is a short video on how to use it:
If your scraping tasks need proxies or need to daily, they also have a cloud option, where you can run your scraping tasks directly on their servers for a monthly fee.
Who should use this web scraping tool?
Companies without developers, marketing teams, product managers...
Pro:
- Simple to use
Con:
- Can't handle complex web scraping scenarios
Parsehub
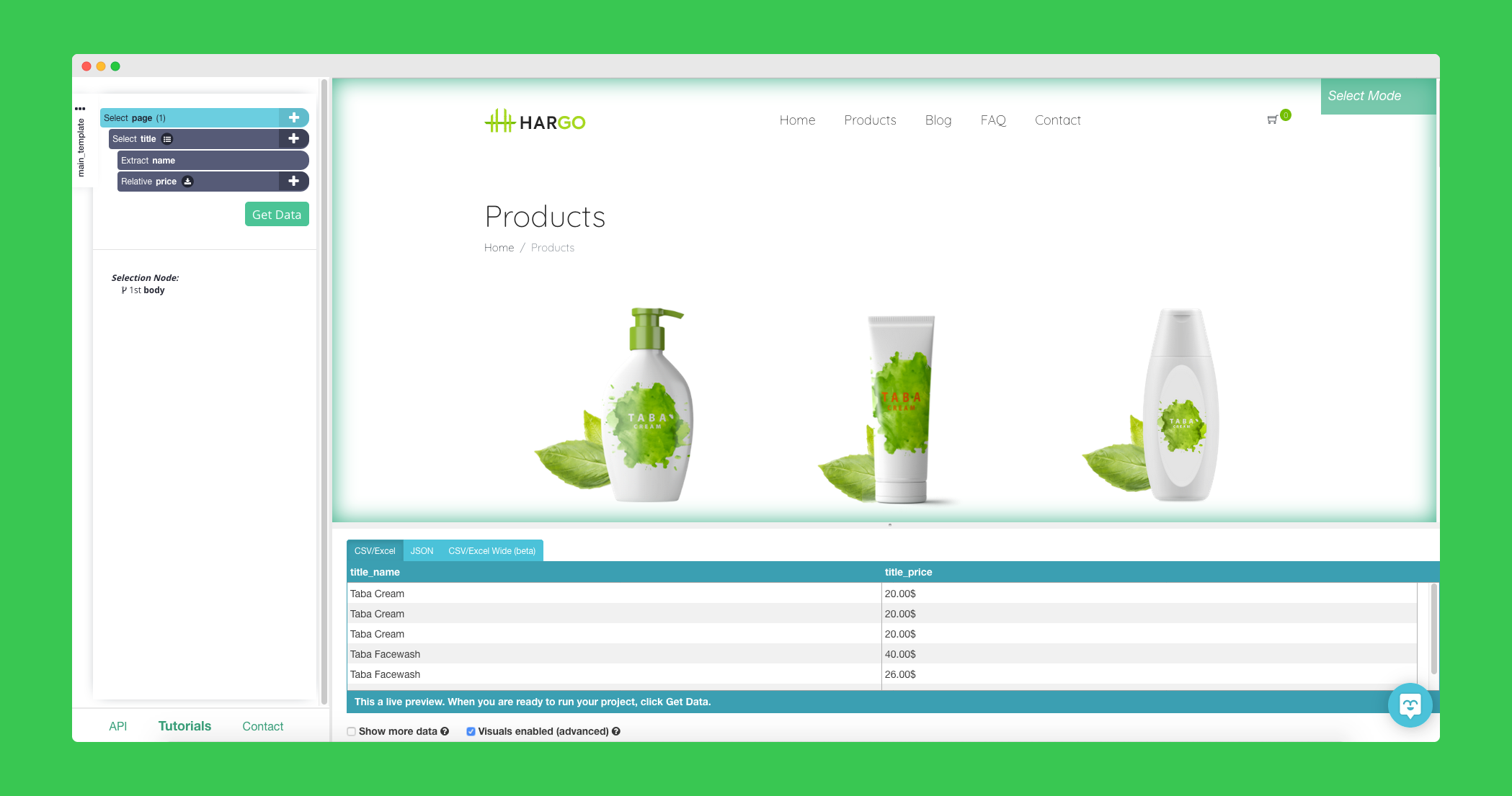
Parsehub is a web scraping desktop application that allows you to scrape the web, even with complicated and dynamic websites/scenarios.
The scraping itself happens on Parsehub servers. You only have to create the instruction within the app.
Lots of visual web scraping tools are very limited when it comes to scraping dynamic websites, not Parsehub. For example, you can:
- Scroll
- Wait for an element to be displayed on the page
- Fill inputs and submit forms
- Scrape data behind a login form
- Download files and images
- Can be cheaper than buying proxies
Pro:
- API access
- Export to JSON/CSV file
- Scheduler (you can choose to execute your scraping task hourly/daily/weekly)
Cons:
- Steep learning curve
- Expensive
Octoparse
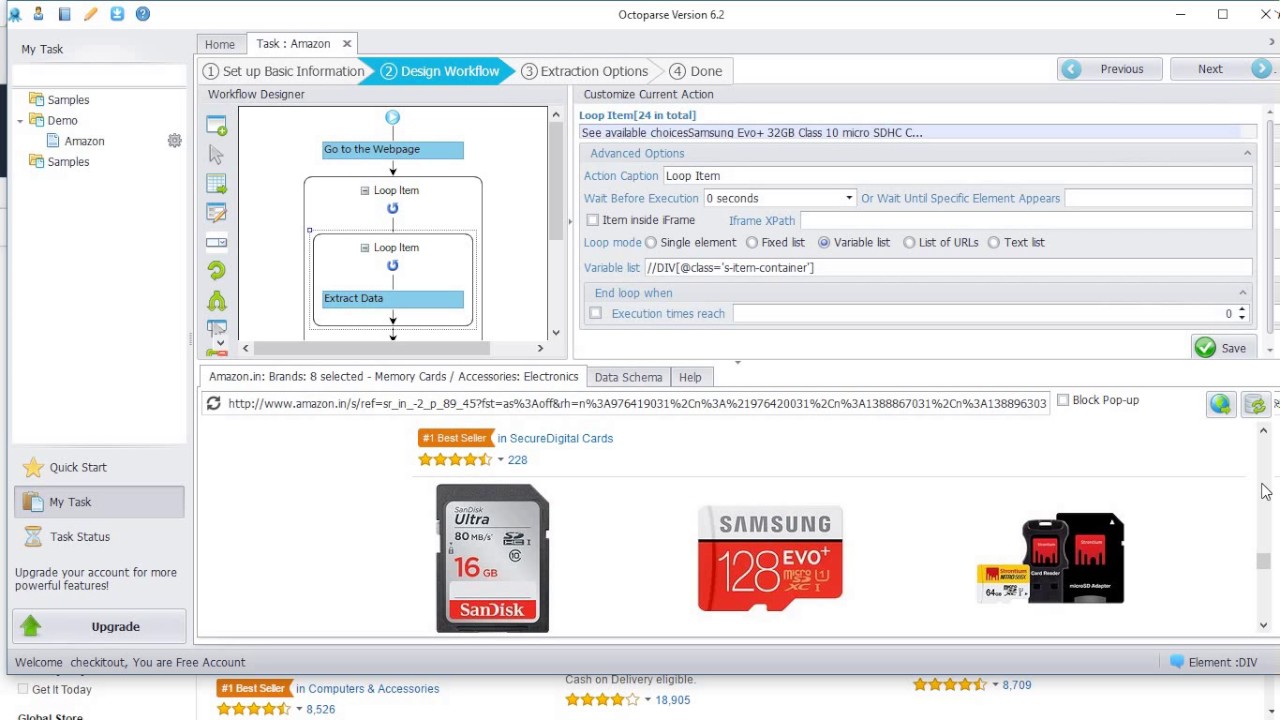
Octoparse is another web scraping tool with a desktop application (Windows only, sorry macOS users 🤷♂️ ).
It is very similar to Parsehub
The pricing is cheaper than Parsehub, but we found the tool more complicated to use.
You can do both cloud extraction (on ParseHub cloud) and local extraction (on your own computer).
Pro:
- Great pricing
Cons:
- Steep learning curve
- Windows only
Simplescraper.io
Simplescraper is an easy-to-use Chrome extension that extracts data from a website.
Simply point and click on an element, name your element, and "voilà".
Here is a little video of how it works:
Pros:
- Simple to use
- Website to data to API in 30 seconds
Cons:
- Much more limited than Octoparse or Parsehub
- Expensive for high volume
DataMiner
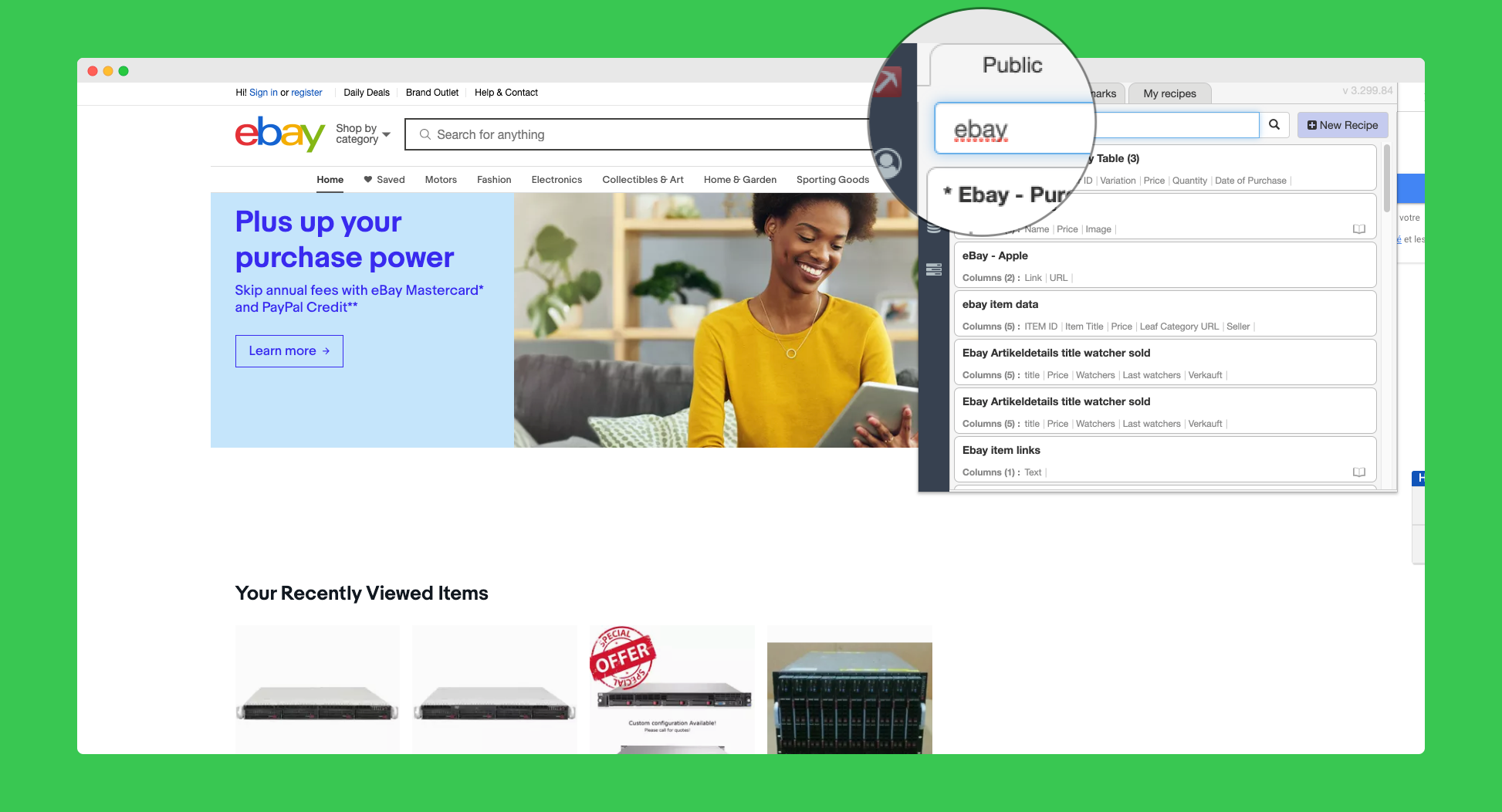
DataMiner is one of the most famous Chrome extensions for web scraping (186k installation and counting). What is unique about DataMiner is that it has a lot of features compared to other extensions.
Generally, Chrome extensions are easier to use than a desktop app like Octoparse or Parsehub but lack lots of features.
DataMiner fits right in the middle. It can handle infinite scroll, pagination, custom Javascript execution, all inside your browser.
One of the great thing about dataminer is that there is a public recipe list that you can search to speed up your scraping. A recipe is a list of steps and rules to scrape a website.
For big websites like Amazon or eBay, you can scrape the search results with a single click, without having to manually click and select the element you want.
Pros:
- Easy-to-use
- Lots of public recipes
- No coding required
Cons:
- It is by far the most expensive tool on our list ($200/mo for 9000 pages scraped per month)
Portia
Portia is another great open source project from ScrapingHub. It's a visual abstraction layer on top of the great Scrapy framework.
This means it allows to create Scrapy spiders without a single line of code, with a visual tool.
Portia is a web application written in Python. You can run it easily thanks to the docker image.
Simply run the following :
docker run -v ~/portia_projects:/app/data/projects:rw -p 9001:9001 scrapinghub/portia
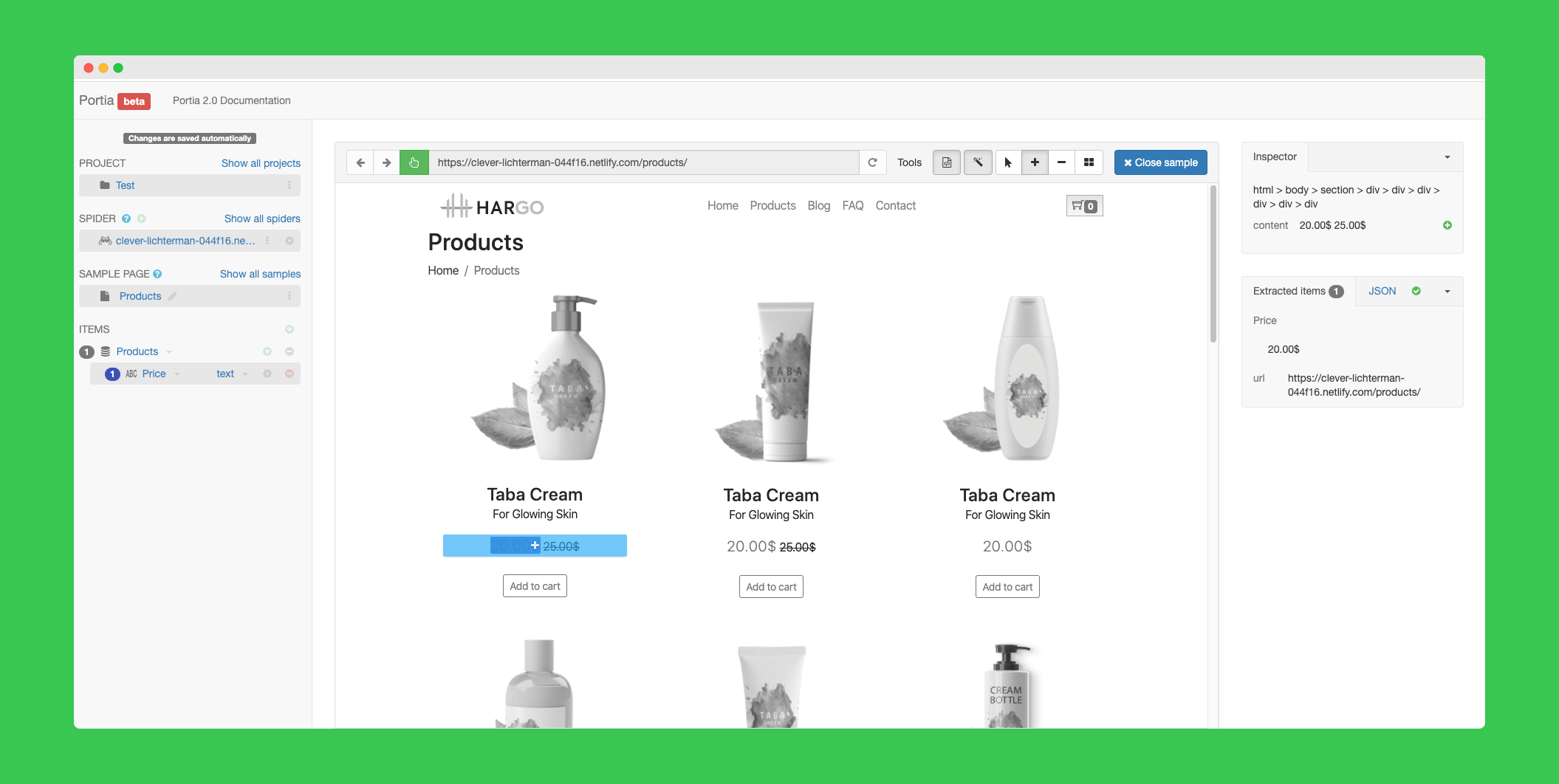
Lots of things can be automated with Portia. When things gets too complicated and custom code/logic needs to be implemented, you can use this tool https://github.com/scrapinghub/portia2code to convert a Portia project to a Scrapy project, to add custom logic.
One of the biggest problem with Portia is that it use the Splash engine to render Javascript-heavy website. It works great in many cases, but has severe limitation compared to Headless Chrome for example. Websites using React.js aren't supported!
Pros:
- Great "low-code" tool for teams already using Scrapy
- Open-source
Cons:
- Limitations regarding Javascript rendering support
WebHarvy
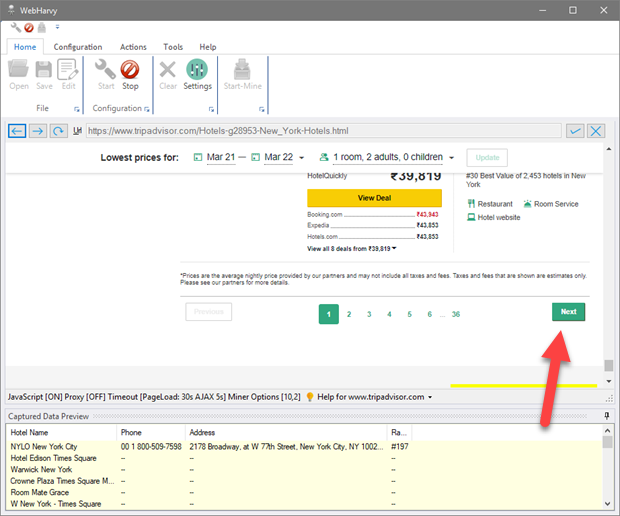
WebHarvy is a desktop application that can scrape website locally (it runs on your computer, not on a cloud server).
It visual scraping feature allows you to define extraction rules just like Octoparse and Parsehub. The difference is that you only pay for the software once, there isn't any monthly billing.
Webharvy is a good software for fast and simple scraping tasks.
However, there are serious limitations. If you want to perform a large-scale scraping task,it can take long because you are limited by the number of CPU cores on your local computer.
It's also complicated to implement complex logic compared to software like Parsehub or Octoparse.
Pros:
- One-time payment
- Great for simple scraping tasks
Cons:
- Limited features compared to competition
- UI isn't as good as Parsehub and Octoparse
- Doesn't support CAPTCHA solving
FMiner
FMiner is another software very similar to Webharvy.
There are three major differences between FMiner and WebHarvy. With FMiner:
- You can record complete sequences with your browser and reproduce them
- You can solve CAPTCHAs
- You can use a custom Python code to handle complex logic
Overall FMiner is a great visual web scraping software.
The only cons we see is the price: $249 for the pro version.
Pros:
- One-time payment
- Great for visual web scraping
Cons:
- UI is a bit old
ProWebScraper
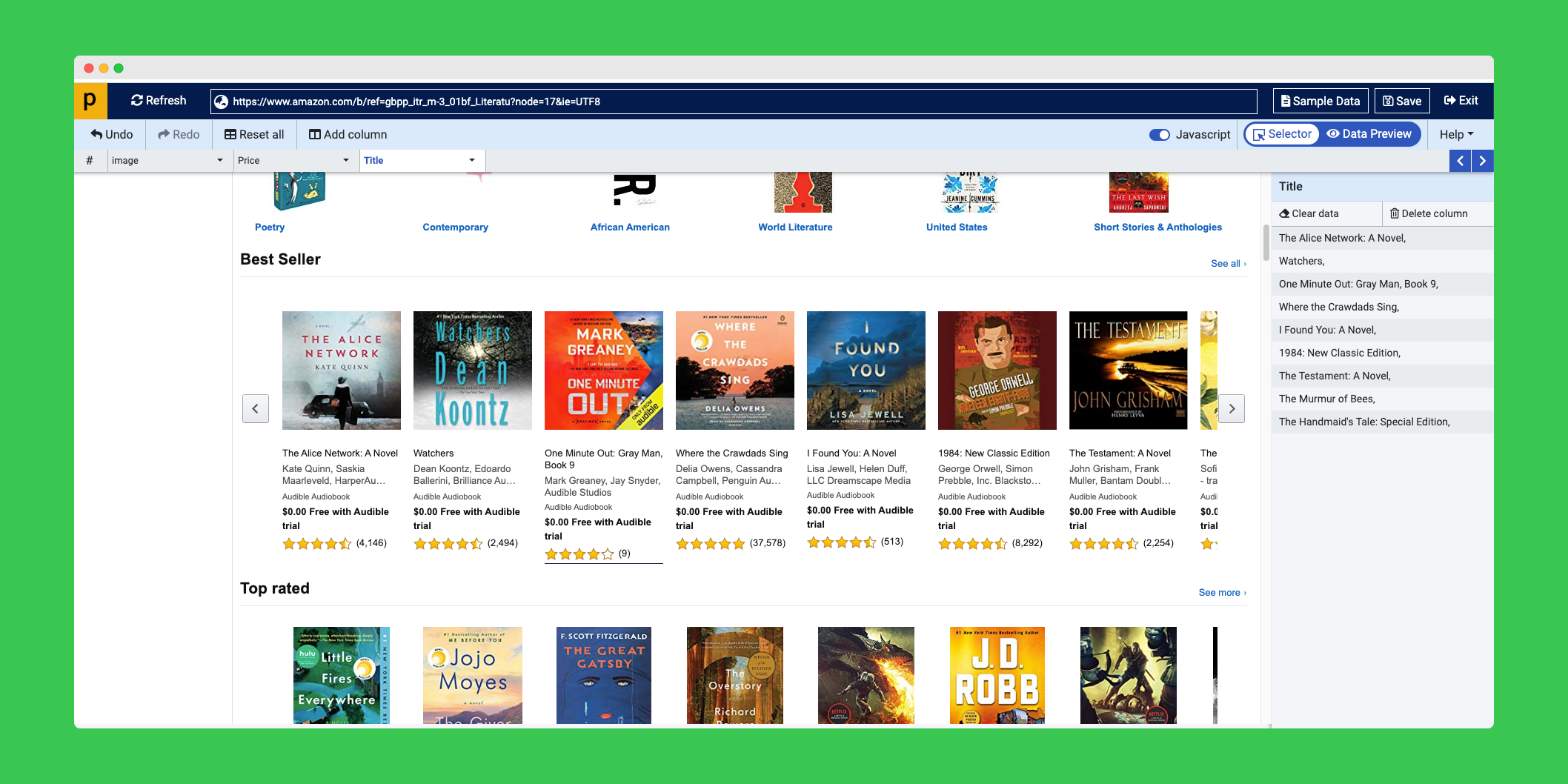
ProWebScraper is a new online visual web scraping tool.
It has many useful features. As usual you can select elements with an easy point-and-click interface. You can export data in many formats. CSV, JSON and even with a REST API.
If it's too complicated, ProWebScraper can also set up the scraper for you for a fee.
Pro:
- Easy set-up
- Runs in the cloud
Cons:
- Expensive ($385/mo for 100k page scraped per month)
Conclusion
This was a long list!
Web scraping can be done by people with various degrees of experience and knowledge. Whether you're a developer wanting to perform large-scale data extraction on lots of websites or a growth-hacker wanting to extract email addresses on directory websites, there are many options!
I hope this blog post will help you choose the right tool for the job :)
Happy web scraping!

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.