Introduction:
In this post, which can be read as a follow-up to our guide about web scraping without getting blocked, we will cover almost all of the tools Python offers to scrape the web. We will go from the basic to advanced ones, covering the pros and cons of each. Of course, we won't be able to cover every aspect of every tool we discuss, but this post should give you a good idea of what each tool does, and when to use one.
Note: When I talk about Python in this blog post you should assume that I talk about Python3.
0. Web Fundamentals
The internet is complex: there are many underlying technologies and concepts involved to view a simple web page in your browser. I don’t have the pretension to explain everything, but I will explain the most important to understand for extracting data from the web.
HyperText Transfer Protocol
HyperText Transfer Protocol (HTTP) uses a client/server model. An HTTP client (a browser, your Python program, cURL, Requests...) opens a connection and sends a message (“I want to see that page : /product”)to an HTTP server (Nginx, Apache...). Then the server answers with a response (the HTML code for example) and closes the connection.
HTTP is called a stateless protocol because each transaction (request/response) is independent. FTP, for example, is stateful.
Basically, when you type a website address in your browser, the HTTP request looks like this:
GET /product/ HTTP/1.1
Host: example.com
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/web\
p,*/*;q=0.8
Accept-Encoding: gzip, deflate, sdch, br
Connection: keep-alive
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit\
/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
In the first line of this request, you can see the following:
- The GET verb or method: This means we request data from the specific path:
/product/. There are other HTTP verbs, and you can see the full list here. - The version of the HTTP protocol: In this tutorial we will focus on HTTP 1.
- Multiple headers fields: Connection, User-Agent... Here is an exhaustive list of HTTP headers
Here are the most important header fields :
- Host: This is the domain name of the server. If no port number is given, it is assumed to be 80.
- User-Agent: This contains information about the client originating the request, including the OS. In this case, it is my web browser (Chrome) on macOS. This header is important because it is either used for statistics (how many users visit my website on mobile vs desktop) or to prevent violations by bots. Because these headers are sent by the clients, they can be modified (“Header Spoofing”). This is exactly what we will do with our scrapers - make our scrapers look like a regular web browser.
- Accept: These are the content types that are acceptable as a response. There are lots of different content types and sub-types: text/plain, text/html, image/jpeg, application/json ...
- Cookie : This header field contains a list of name-value pairs (name1=value1;name2=value2). These session cookies are used to store data. Cookies are what websites use to authenticate users and/or store data in your browser. For example, when you fill a login form, the server will check if the credentials you entered are correct. If so, it will redirect you and inject a session cookie in your browser. Your browser will then send this cookie with every subsequent request to that server.
- Referrer: The Referrer header contains the URL from which the actual URL has been requested. This header is important because websites use this header to change their behavior based on where the user came from. For example, lots of news websites have a paying subscription and let you view only 10% of a post, but if the user comes from a news aggregator like Reddit, they let you view the full content. They use the referrer to check this. Sometimes we will have to spoof this header to get to the content we want to extract.
And the list goes on...you can find the full header list here.
A server will respond with something like this:
HTTP/1.1 200 OK
Server: nginx/1.4.6 (Ubuntu) Content-Type: text/html; charset=utf-8 <!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" /> ...[HTML CODE]
On the first line, we have a new piece of information, the HTTP code 200 OK. This means the request has succeeded. As for the request headers, there are lots of HTTP codes. They are split into four common classes: 2XX for successful requests, 3XX for redirects, 4XX for bad requests (the most famous being "404 Not Found"), and 5XX for server errors.
Then, if you are sending this HTTP request with your web browser, the browser will parse the HTML code, fetch all the eventual assets (Javascript files, CSS files, images...), and render the result into the main window.
We will go through the different ways to perform HTTP requests with Python and extract the data we want from the responses.
1. Manually Opening a Socket and Sending the HTTP Request
Socket
The most basic way to perform an HTTP request in Python is to open a socket and manually send the HTTP request.
import socket
HOST = 'www.google.com' # Server hostname or IP address
PORT = 80 # Port
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = (HOST, PORT)
client_socket.connect(server_address)
request_header = b'GET / HTTP/1.0\r\nHost: www.google.com\r\n\r\n'
client_socket.sendall(request_header)
response = ''
while True:
recv = client_socket.recv(1024)
if not recv:
break
response += str(recv)
print(response)
client_socket.close()
Now that we have the HTTP response, the most basic way to extract data from it is to use regular expressions.
Regular Expressions
A regular expression (RE or regex) is a search pattern for strings.
With regex, you can search for a particular character/word in a bigger body of text.
For example, you could identify all phone numbers in a web page.
You can also replace items with a regex. For example, you could replace all uppercase tags in a poorly formatted HTML with lowercase tags.
You can also validate some inputs ...
The pattern used by a regex is applied from left to right, and each source character is only used once.
You may be wondering why it is important understand regular expressions when doing web scraping.
After all, there are many different Python modules to parse HTML, with XPath and CSS selectors.
In an ideal semantic world, data is easily machine-readable, and the information is embedded inside relevant HTML elements, with meaningful attributes.
But the real world is messy. You will often find huge amounts of text inside a p element. For example, if you want to extract specific data inside a large text (a price, a date, a name...), you will have to use regular expressions.
Note: Here is a great website to test your regex: https://regex101.com/. Also, here is an awesome blog to learn more about them. This post will only cover a small fraction of what you can do with regex.
Regular expressions can be useful when you have this kind of data:
<p>Price : 19.99$</p>
We could select this text node with an Xpath expression and then use this kind of regex to extract the price:
^Price\s:\s(\d+\.\d{2})\$
To extract the text inside an HTML tag, it is annoying but doable to use a regex:
import re
html_content = '<p>Price : 19.99$</p>'
m = re.match('<p>(.+)<\/p>', html_content)
if m:
print(m.group(1))
As you can see, manually sending the HTTP request with a socket and parsing the response with regular expression can be done, but it's complicated and there are higher-level API that can make this task easier.
2. urllib3 & LXML
Disclaimer: It is easy to get lost in the urllib universe in Python. The standard library contains urllib and urllib2 (and sometimes urllib3). In Python3 urllib2 was split into multiple modules and urllib3 won't be part of the standard library anytime soon. This confusing situation will be the subject of another blog post. In this section, I've decided to only talk about urllib3 because it is widely used in the Python world, including by Pip and Requests.
Urllib3 is a high-level package that allows you to do pretty much whatever you want with an HTTP request. We urllib3 we could do what we did in the previous section with way fewer lines of code.
import urllib3
http = urllib3.PoolManager()
r = http.request('GET', 'http://www.google.com')
print(r.data)
As you can see, this is much more concise than the socket version. Not only that, the API is straightforward. Also, you can easily do many other things, like adding HTTP headers, using a proxy, POSTing forms ...
For example, had we decided to set some headers and use a proxy, we would only have to do the following (you can learn more about proxy servers at bestproxyreviews.com):
import urllib3
user_agent_header = urllib3.make_headers(user_agent="<USER AGENT>")
pool = urllib3.ProxyManager(f'<PROXY IP>', headers=user_agent_header)
r = pool.request('GET', 'https://www.google.com/')
See? There are exactly the same number of lines. However, there are some things that urllib3 does not handle very easily. For example, if we want to add a cookie, we have to manually create the corresponding headers and add it to the request.
There are also things that urllib3 can do that requests can't: creation and management of a pool and proxy pool, control of retry strategy for example.
To put it simply, urllib3 is between Requests and Socket in terms of abstraction, although it's way closer to requests than socket.
Next, to parse the response, we are going to use the LXML package and XPath expressions.
XPath
XPath is a technology that uses path expressions to select nodes or node- sets in an XML document (or HTML document). As with the Document Object Model, Xpath has been a W3C standard since 1999. Although XPath is not a programming language in itself, it allows you to write expressions that can directly access a specific node, or a specific node-set, without having to go through the entire HTML tree (or XML tree).
Think of XPath as regex, but specifically for XML/HMTL.
To extract data from an HTML document with XPath we need three things:
- an HTML document
- some XPath expressions
- an XPath engine that will run those expressions
To begin, we will use the HTML we got from urllib3,. Imagine we want to extract all of the links from the Google homepage.
So, we will use one simple XPath expression: //a. And we will use LXML to run it. LXML is a fast and easy to use XML and HTML processing library that supports XPATH.
Installation:
pip install lxml
Below is the code that comes just after the previous snippet:
from lxml import html
# We reuse the response from urllib3
data_string = r.data.decode('utf-8', errors='ignore')
# We instantiate a tree object from the HTML
tree = html.fromstring(data_string)
# We run the XPath against this HTML
# This returns an array of element
links = tree.xpath('//a')
for link in links:
# For each element we can easily get back the URL
print(link.get('href'))
And the output should look like this:
https://books.google.fr/bkshp?hl=fr&tab=wp
https://www.google.fr/shopping?hl=fr&source=og&tab=wf
https://www.blogger.com/?tab=wj
https://photos.google.com/?tab=wq&pageId=none
http://video.google.fr/?hl=fr&tab=wv
https://docs.google.com/document/?usp=docs_alc
...
https://www.google.fr/intl/fr/about/products?tab=wh
Keep in mind that this example is really really simple and doesn't show you how powerful XPath can be (Note: This XPath expression should have been changed to //a/@href to avoid having to iterate on links to get their href ).
If you want to learn more about XPath, you can read this helpful introduction. The LXML documentation is also well-written and is a good starting point.
XPath expressions, like regex, are powerful and one of the fastest way to extract information from HTML. And like regex, XPath can quickly become messy, hard to read, and hard to maintain.
If you'd like to learn more about XPath, do not hesitate to read my dedicated blog post about XPath applied to web scraping.
toto3. Requests & BeautifulSoup
Requests
Requests is the king of Python packages. With more than 11,000,000 downloads, it is the most widely used package for Python.
Installation:
pip install requests
Making a request with Requests (no comment) is easy:
import requests
r = requests.get('https://www.scrapingninja.co')
print(r.text)
With Requests, it is easy to perform POST requests, handle cookies, query parameters... You an also download images with Requests.
On the following page, you will learn to use Requests with proxies. This is almost mandatory for scraping the web at scale.
Authentication to Hacker News
Let's say we want to create a tool to automatically submit our blog post to Hacker news or any other forum, like Buffer. We would need to authenticate to those websites before posting our link. That's what we are going to do with Requests and BeautifulSoup!
Here is the Hacker News login form and the associated DOM:
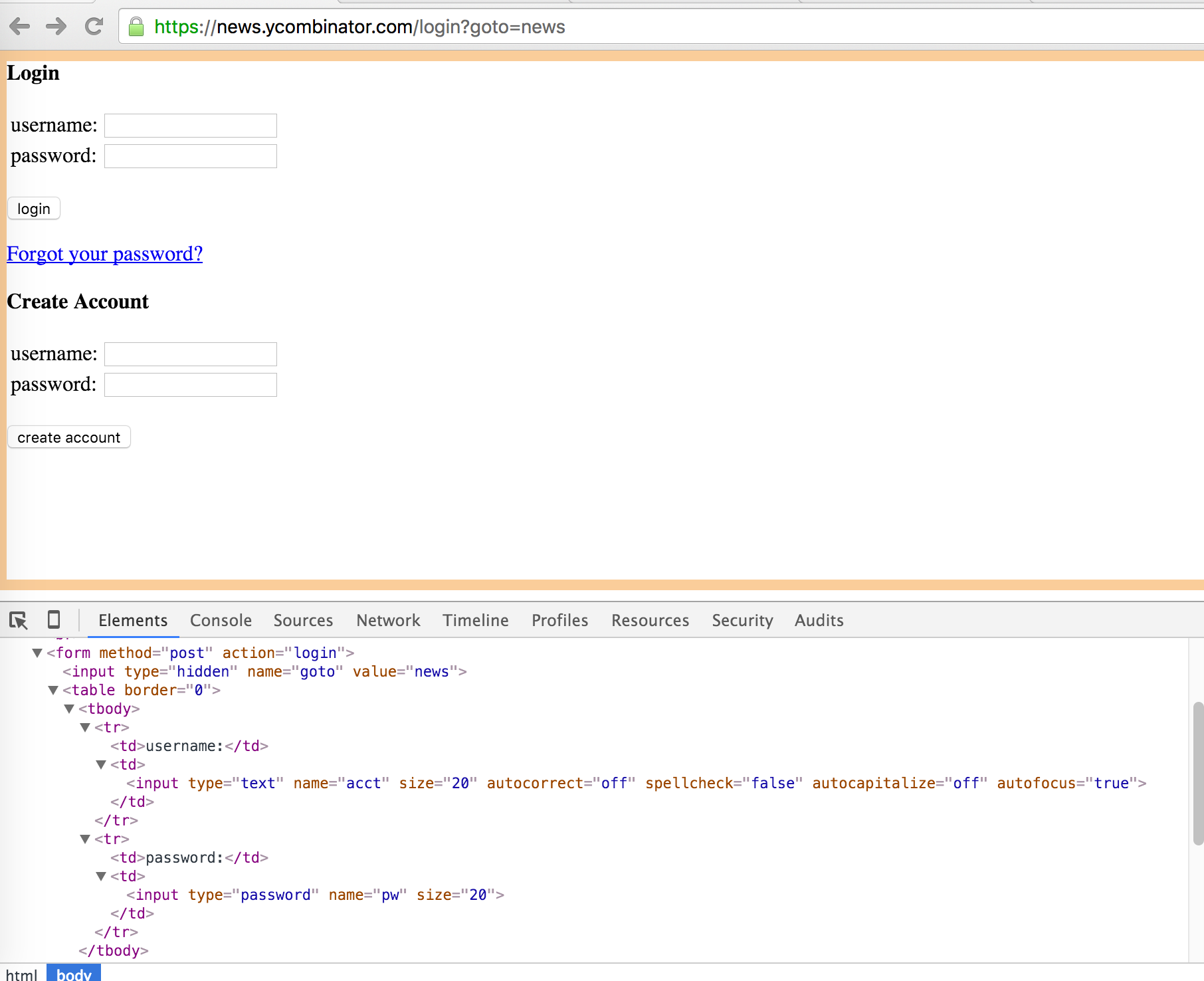
There are three <input> tags on this form. The first one has a type hidden with a name "goto", and the two others are the username and password.
If you submit the form inside your Chrome browser, you will see that there is a lot going on: a redirect and a cookie is being set. This cookie will be sent by Chrome on each subsequent request in order for the server to know that you are authenticated.
Doing this with Requests is easy. It will handle redirects automatically for us, and handling cookies can be done with the Session object.
BeautifulSoup
The next thing we will need is BeautifulSoup, which is a Python library that will help us parse the HTML returned by the server, to find out if we are logged in or not.
Installation:
pip install beautifulsoup4
So, all we have to do is POST these three inputs with our credentials to the /login endpoint and check for the presence of an element that is only displayed once logged in:
import requests
from bs4 import BeautifulSoup
BASE_URL = 'https://news.ycombinator.com'
USERNAME = ""
PASSWORD = ""
s = requests.Session()
data = {"goto": "news", "acct": USERNAME, "pw": PASSWORD}
r = s.post(f'{BASE_URL}/login', data=data)
soup = BeautifulSoup(r.text, 'html.parser')
if soup.find(id='logout') is not None:
print('Successfully logged in')
else:
print('Authentication Error')
In order to learn more about BeautifulSoup, we could try to extract every links on the homepage.
By the way, Hacker News offers a powerful API, so we're doing this as an example, but you should use the API instead of scraping it!
The first thing we need to do is inspect Hacker News's home-page to understand the structure and the different CSS classes that we will have to select:
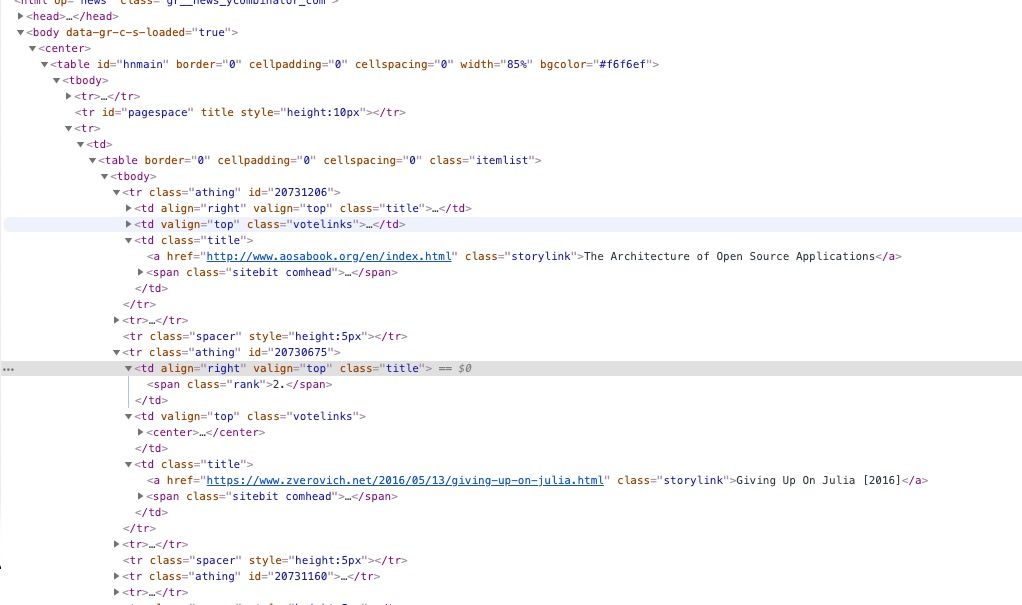
We can see that all of the posts are inside a <tr class="athing">. So, the first thing we will need to do is to select all of these tags. This can be easily done with the following:
links = soup.findAll('tr', class_='athing')
Then, for each link, we will extract its id, title, url and rank:
import requests
from bs4 import BeautifulSoup
r = requests.get('https://news.ycombinator.com')
soup = BeautifulSoup(r.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
formatted_links = []
for link in links:
data = {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(links[0].td.span.text.replace('.', ''))
}
formatted_links.append(data)
print(formatted_links)
As you can see, Requests and BeautifulSoup are great libraries for extracting data and automate different actions by posting forms. If you want to do large-scale web scraping projects, you could still use Requests, but you would need to handle lots of parts yourself.
If you want to learn more about Python, BeautifulSoup and particularly CSS selectors, I recommend reading this. For POST requests, see this article: How to send POST with Requests
When you need to scrape a lots of webpages, there are many things you have to take care of:
- Finding a way to parallelize your code to make it faster
- Handling errors
- Storing results
- Filtering results
- Throttling your request so you don't over-load the server
Fortunately for us, tools exist that can handle those for us.
💡 We released a new feature that makes this whole process way simpler. You can now extract data from HTML with one simple API call. Feel free to check the documentation here.
Grequests
While the requests package is easy-to-use, you might find it a bit slow if you have hundreds of pages to scrape.
The requests package, out of the box, only allows you to make synchronous requests, meaning that if you have 25 URLs to scrape, you will have to do it one by one.
So if one page takes ten seconds to be fetched, will take you 25*10 seconds to fetch 25 pages.
import requests
# An array with 25 urls
urls = [...]
for url in urls:
result = requests.get(url)
The easiest way to speed-up this process is to make several calls at the same time. This means that instead of sending every request sequentially, you can send requests in batches of five.
If you send five requests simultaneously, you will wait for all of them to complete. Then, you will send another batch of five requests and wait again, repeating this until you don't have any more URLs to scrape.
This way, you can send 25 requests in five batches of five requests. Meaning all the URLs can be scrape in 5*10=50 seconds instead of 25*10=250 seconds.
Usually, this kind of behaviour is implemented using thread-based parallelism. It can be tricky for beginners. Fortunately, there is a version of the requests package that does all the hard work for us.
It's called grequest, for g + requests, with the g standing for gevent, an asynchronous Python API widely used for web application.
This library allows us to send multiple requests at the same time and in an easy and elegant way.
Here is how to send our 25 initial URLs in batches of 5:
# pip install grequests
import grequests
BATCH_LENGTH = 5
# An array with 25 urls
urls = [...]
# Our empty results array
results = []
while urls:
# get our first batch of 5 URLs
batch = urls[:BATCH_LENGTH]
# create a set of unsent Requests
rs = (grequests.get(url) for url in batch)
# send them all at the same time
batch_results = grequests.map(rs)
# appending results to our main results array
results += batch_results
# removing fetched URLs from urls
urls = urls[BATCH_LENGTH:]
print(results)
# [<Response [200]>, <Response [200]>, ..., <Response [200]>, <Response [200]>]
And that's it. Grequest is perfect for small scripts but is not suited for production code or high-scale web scraping. For that, we have Scrapy 👇.
4. Web Crawling Frameworks
Scrapy

Scrapy is a powerful Python web scraping and web crawling framework.
Scrapy provides many features to download web pages asynchronously, process them and save them. It handles multithreading, crawling (the process of going from link to link to find every URL in a website), sitemap crawling, and more.
Scrapy also has an interactive mode called the Scrapy Shell. With the Scrapy Shell you can test your scraping code quickly, like XPath expressions or CSS selectors.
The downside of Scrapy is that the learning curve is steep. There is a lot to learn.
To follow up on our example about Hacker News, we are going to write a Scrapy Spider that scrapes the first 15 pages of results, and saves everything in a CSV file.
You can easily install Scrapy with pip:
pip install Scrapy
Then you can use the Scrapy CLI to generate the boilerplate code for our project:
scrapy startproject hacker_news_scraper
Inside hacker_news_scraper/spider we will create a new Python file with our Spider's code:
from bs4 import BeautifulSoup
import scrapy
class HnSpider(scrapy.Spider):
name = "hacker-news"
allowed_domains = ["news.ycombinator.com"]
start_urls = [f'https://news.ycombinator.com/news?p={i}' for i in range(1,16)]
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.findAll('tr', class_='athing')
for link in links:
yield {
'id': link['id'],
'title': link.find_all('td')[2].a.text,
"url": link.find_all('td')[2].a['href'],
"rank": int(link.td.span.text.replace('.', ''))
}
There is a lot of convention in Scrapy. Here we define an array of starting URLs. The attribute name will be used to call our Spider with the Scrapy command line.
The parse method will be called on each URL in the start_urls array
We then need to tune Scrapy a bit in order for our Spider to behave nicely against the target website.
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True
# The initial download delay
AUTOTHROTTLE_START_DELAY = 5
You should always turn this on. It will make sure the target website is not slowed down by your spiders. It does this by analyzing the response time and adapting the numbers of concurrent threads.
You can run this code with the Scrapy CLI and with different output formats (CSV, JSON, XML...):
scrapy crawl hacker-news -o links.json
And that's it! You will now have all your links in a nicely formatted JSON file.
There is much more to say about this tool. So, if you wish to learn more, don't hesitate to check out our dedicated blog post about web scraping with Scrapy.
PySpider
PySpider is an alternative to Scrapy, albeit a bit outdated. Its last release is from 2018. However it is still relevant because it does many things that Scrapy does not out of the box.
First, PySpider works well with JavaScript pages (SPA and Ajax call) because it comes with PhantomJS, a headless browsing library. In Scrapy, you would need to install middlewares to do this.
Also, PySpider comes with a nice UI that makes it easy to monitor all of your crawling jobs.
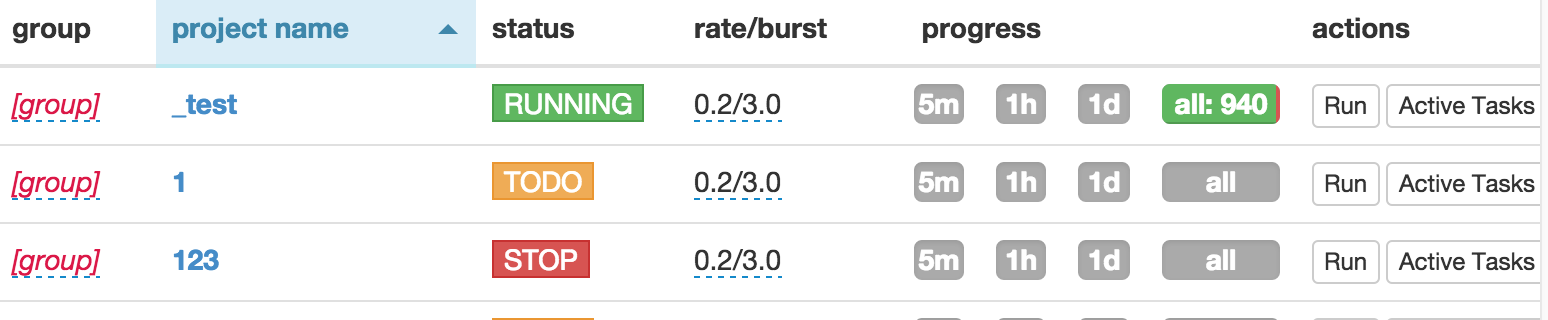
However, you might still prefer to use Scrapy for several reasons:
- A much better documentation than PySpider with easy-to-understand guides
- A built-in HTTP cache system that can speed up your program
- Automatic HTTP authentication
- 3XX redirection supported through HTML meta refresh
5. Headless browsing
Selenium & Chrome
Scrapy is great for large-scale web scraping tasks. However, it is not enough if you need to scrape a Single Page Application written with Javascript frameworks because it won't be able to render the Javascript code.
It can be challenging to scrape SPAs because there are often lots of AJAX calls and websockets connections involved. If performance is an issue, always try to reproduce the Javascript code. This means manually inspecting all of the network calls with your browser inspector, and replicating the AJAX calls containing the interesting data.
In some cases, there are too many asynchronous HTTP calls involved to get the data you want and it can be easier to render the page in a headless browser.
Another great use case would be to take a screenshot of a page, and this is what we are going to do with the Hacker News homepage (again !)
You can install the Selenium package with pip:
pip install selenium
You will also need Chromedriver:
brew install chromedriver
Then, we just have to import the Webdriver from the Selenium package, configure Chrome with headless=True and set a window size (otherwise it is really small):
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=r'/usr/local/bin/chromedriver')
driver.get("https://news.ycombinator.com/")
driver.save_screenshot('hn_homepage.png')
driver.quit()
You should get a nice screenshot of the homepage:

You can do many more with the Selenium API and Chrome:
- Executing Javascript
- Filling forms
- Clicking on Elements
- Extracting elements with CSS selectors / XPath expressions
Selenium and Chrome in headless mode are the ultimate combination to scrape anything you want. You can automate everything that you could do with your regular Chrome browser.
The big drawback is that Chrome needs lots of memory / CPU power. With some fine-tuning you can reduce the memory footprint to 300-400mb per Chrome instance, but you still need 1 CPU core per instance.
Don't hesitate to check out our in-depth article about Selenium and Python.
If you want to run several Chrome instances concurrently, you will need powerful servers (the cost goes up quickly) and constant monitoring of resources.
RoboBrowser
RoboBrowser is a Python library that will allow you to browse the web by wrapping requests and BeautifulSoup in an easy-to-use interface.
It is not a headless browser per se because it does not rely on any web-browser binary. Instead, it's a lightweight library that allows you to write scripts as if you were executing them in a "browser-like" environment.
For example, if you want to login to Hacker-News, instead of manually crafting a request with requests, you can write a script that will populate the form and "press" the login button:
# pip install RoboBrowser
from robobrowser import RoboBrowser
browser = RoboBrowser()
browser.open('https://news.ycombinator.com/login')
# Get the signup form
signin_form = browser.get_form(action='login')
# Fill it out
signin_form['acct'].value = 'account'
signin_form['password'].value = 'secret'
# Submit the form
browser.submit_form(signin_form)
As you can see, the code is written as if you were manually doing the task in a real browser, even though it is not a real headless browsing library.
RoboBrowser is cool because its lightweight approach allows you to easily parallelize it on your computer. However, because it's not using a real browser, it won't be able to deal with JavaScript execution like AJAX calls or Single Page Application.
Unfortunately, its documentation is also lightweight, and I would not recommend it for newcomers or people not already used to the BeautilfulSoup or requests API.
6. Scraping Reddit data
Sometimes you don't even have to scrape the data using an HTTP client or a headless browser. You can directly use the API exposed by the target website. That's what we are going to see with the Reddit API.
To access the API, we're going to use Praw, a great Python package that wraps the Reddit API.
To install it:
pip install praw
Then, you will need to get an API key. Go to https://www.reddit.com/prefs/apps .
Scroll to the bottom and click on create app:
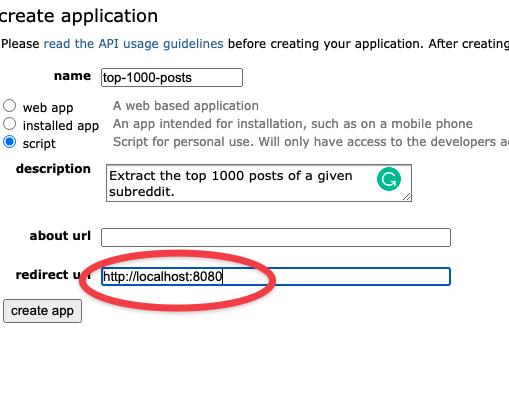
Make sure to fill the redirect URI with http://localhost:8080, as explained in the Praw documentation.
After clicking on create app, you will see the different information you will need to access the Reddit API:
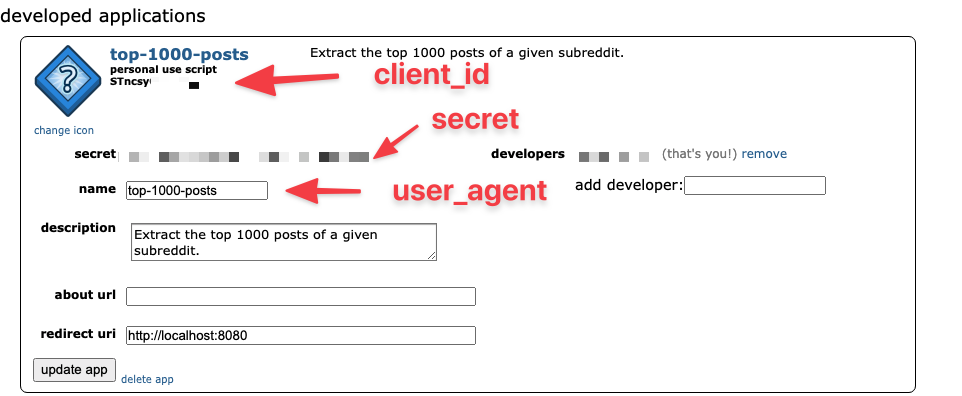
Now we are going to get the top 1,000 posts from /r/Entrepreneur and export it to a CSV file.
import praw
import csv
reddit = praw.Reddit(client_id='you_client_id', client_secret='this_is_a_secret', user_agent='top-1000-posts')
top_posts = reddit.subreddit('Entrepreneur').top(limit=1000)
with open('top_1000.csv', 'w', newline='') as csvfile:
fieldnames = ['title','score','num_comments','author']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for post in top_posts:
writer.writerow({
'title': post.title,
'score': post.score,
'num_comments': post.num_comments,
'author': post.author
})
As you can see, the extraction part is only three lines of Python!
There are many other use cases for Praw. You can do all kinds of crazy things, like analyzing sub reddits in real-time with sentiment analysis libraries, predicting the next $GME ...
Conclusion
Here is a quick recap table of every technology we discussed in this blog post. Do not hesitate to comment if you know some resources that you feel belong here.
| Name | socket | urllib3 | requests | scrapy | selenium |
|---|---|---|---|---|---|
| Ease of use | - - - | + + | + + + | + + | + |
| Flexibility | + + + | + + + | + + | + + + | + + + |
| Speed of execution | + + + | + + | + + | + + + | + |
| Common use case | -Writing low-level programming interface | -High level application that needs fine control over HTTP (pip, aws client, requests, streaming) | -Calling an API -Simple application (in terms of HTTP needs) |
-Crawling an important list of websites - Filtering, extracting and loading scraped data |
-JS rendering -Scraping SPA -Automated testing -Programmatic screenshot |
| Learn more | - Official documentation - Great tutorial 👍 |
- Official documentation - PIP usage of urllib3, very interesting |
- Official documentation - Requests usage of urllib3 |
- Official documentation - Scrapy overview | - Official documentation - Scraping SPA |
I hope you enjoyed this blog post! This was a quick introduction to the most used Python tools for web scraping. In the next posts we're going to go deeper with each tools or topics like XPath and CSS selectors.
If you wan to learn more about HTTP clients in Python, we just released this guide about the best Python HTTP clients.
Happy Scraping!

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.